Data Cleaning in Python
Lets starts the discussion with Data Science, the subject which require lots of data to gain the insights with help various scientific methods, algorithms, and processes. With the help of data science we are able to achieve the complex tasks with less efforts which were either not possible or required a great deal more time and energy, a decade ago. To whatever sector discuss whether it is Entertainment, Healthcare, designing auto-nomous self driving cars, and many more the contribution of data science is growing day by day.
Data science is all about getting the data sets and learning from it. These data sets are collected from world-wide and are known as raw data or source data. Do all these informations are correct or ready for analysis? The answer is No. These data sets are modified as per our needs and then analysed. Here, data cleaning comes into the role.
What is Data Cleaning ?
We are collecting the source data from various sources which might involve some garbage data, some of them would be repeating or some data might be missing. If we are training and analysis from these data sets, there is huge chance of getting unrealistic outcomes. So, we undergo a process of correcting these data sets, removing duplicate and corrupted ones and these process is known as Data Cleaning.
According to wikipedia, Data Cleaning is “the process of detecting and correcting (or removing) corrupt or inaccurate records from a record set, table, or database and refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty or coarse data.”
From definition it is clear that the motive of data cleaning is to extract complete, correct, accurate and relavant data.

Data Cleaning in Python
We would be discussing various steps in the process of data cleaning using numpy and pandas library of python.
Requirements :
- python
- numpy
- pandas
We need to import dataset using pandas which is stored as dataframe, 2-D mutable data structure which stores data in form of row and column.
Here we are using bike_buyers.csv file from Kaggle. https://www.kaggle.com/heeraldedhia/bike-buyers
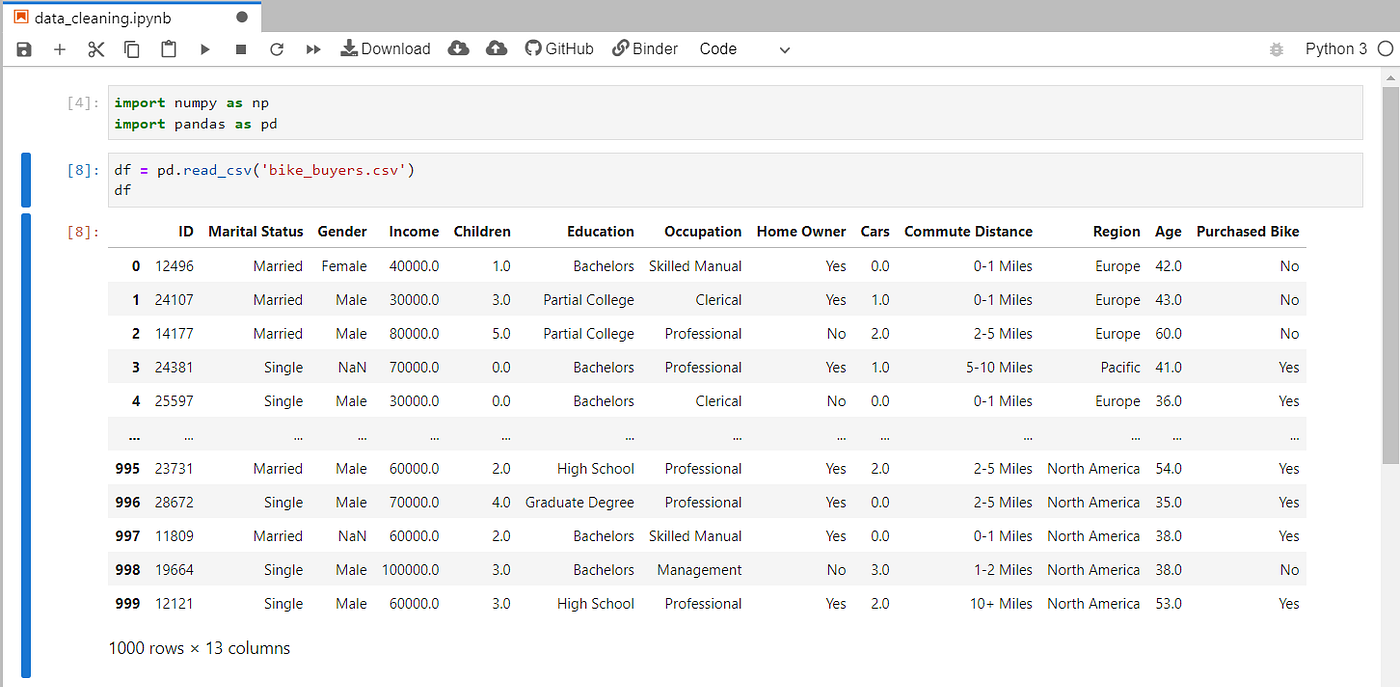
importing data from file using pandas
Replacing missing data with some values.
There might be some fields in data frame which are null that needs to replaced with some values.
First we check whether there are missing values or not, if there is any missing value we replace those values with non null values.
To check if fields are null, pandas provide isnull() function.

We can also check on any particular column using isnull().any() and we also count number of columns having atleat one null value.
To fill the null values, pandas provide fillna() function to fill non null values.
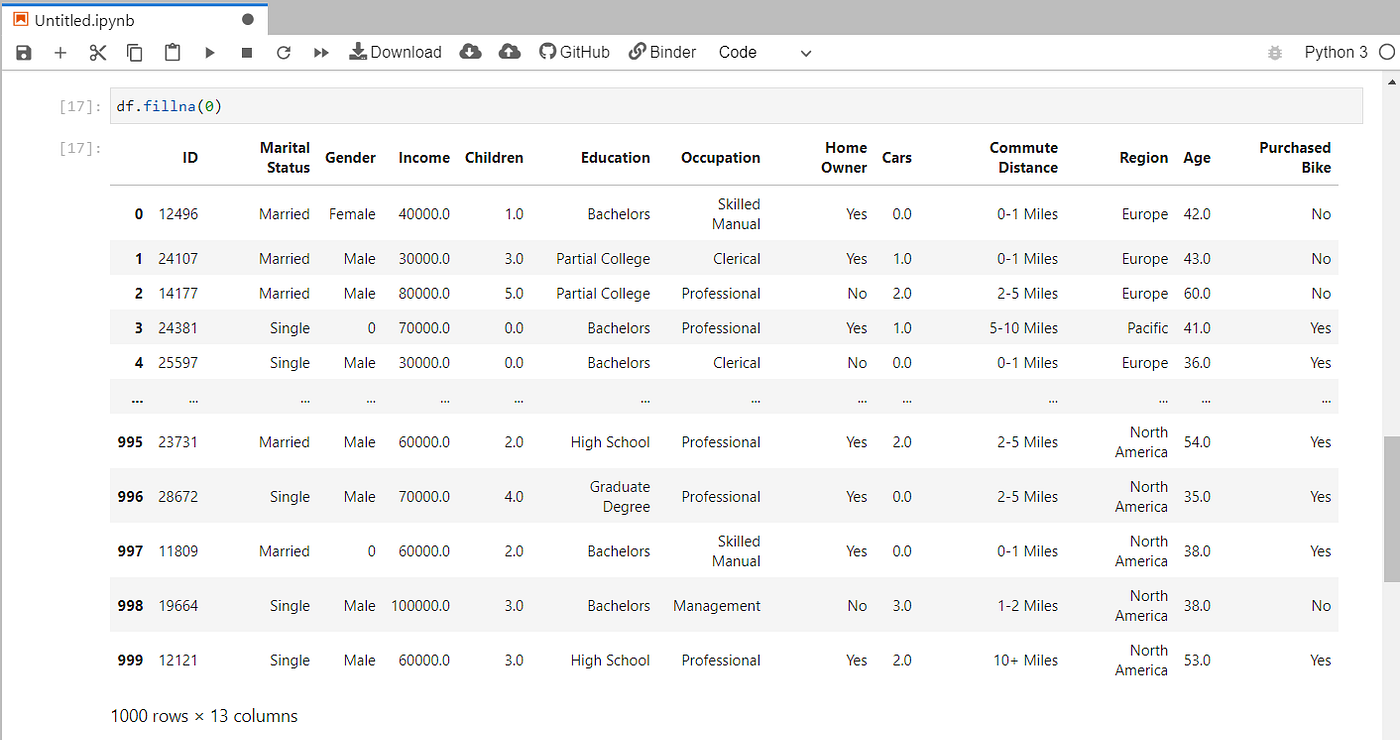
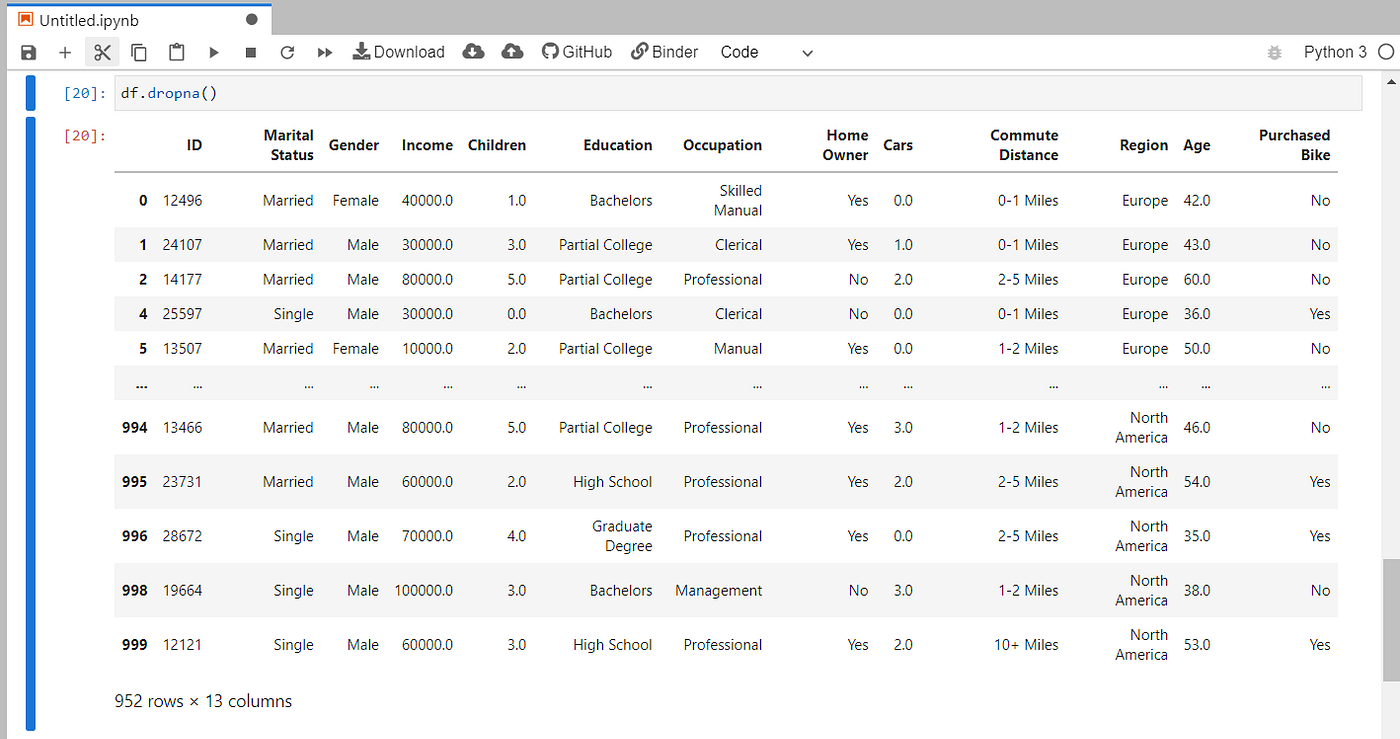
We can also drop the rows containing null values. For such actions pandas provide dropna() function.
Dropping unusable columns.
We ignore the data which are not required in training the model from the dataframe using drop() function.

Removing duplicate data.
The dataframe might contain some rows which are having same values and they all will have same contribution to the model. So we keep only one such row and remove the remainings.
Using duplicated(), we can know whether there are dupicate rows are now. If there are any duplicate rows, we can drop them using drop_duplicates().
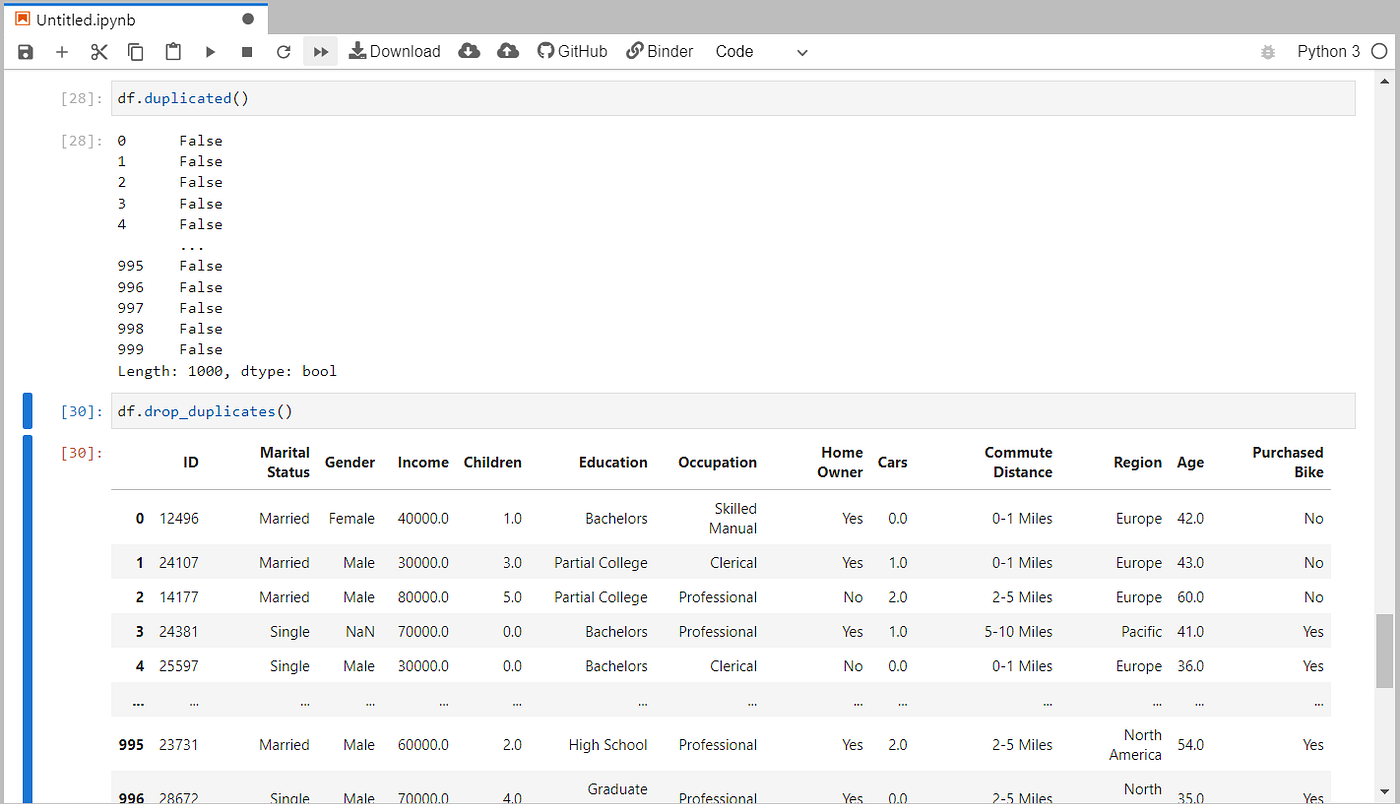
After removing null, duplicate, and incorrect values, the cleaned data set is obtained and it is ensured that obtained data set is making sense.
Conclusion
After the completing the cleaning process on data, cleaned data is re-evaluated and its accuracy is checked. If the data still seems to be incomplete, we further collect on the information from various resource, repeat the same process of cleaning. Completeness is a little more challenging to achieve accuracy or quality in the dataset.
After performing all these operations, the data set is ready to be processed for next step of data science.